
트랜스포머는 Attention 메커니즘을 이해한 뒤 읽는 것을 추천한다.
트랜스포머는 NLP에서의 예제가 풍부하며, 그외 다른 State-of-the-Art (SOTA) 기술의 기반이 되는 알고리즘이다.
특히 기계 번역 분야에서 이 모델은 seq2seq의 구조인 인코더-디코더를 따르면서도, RNN을 사용하지 않고도 RNN보다 우수한 성능을 보여주었다.
필자는 아직도 트랜스포머에 대해 공부하고 있으며, 트랜스포머 자체가 방대하고 복잡하게 설계된 알고리즘이기에, 여러 차시로 나눠서 트랜스포머에 대해 설명하고자 한다.
요약본의 상당 부분은 유원준 & 안상준 저의 <딥러닝을 이용한 자연어처리 입문> 책을 참고하였음을 사전에 밝힌다.
1. 기존 seq2seq 모델의 한계와 Transformer의 동작원리
seq2seq 모델의 기본 구조는 인코더-디코더 구조이다.
이때 인코더는 입력 시퀀스를 차례대로 받아서 모든 정보를 하나의 벡터 표현 압축,
은닉 상태의 값 (컨텍스트 벡터)를 디코더로 넘기며 벡터표현을 통해 출력 시퀀스를 만들어낸다.
이 과정에서 입력 시퀀스가 압축되기에 일부 정보 손실을 피할 수 없고, 이것에 대한 보완책으로 attention 메커니즘이 사용되었다.
Transformer는 "RNN의 보정용으로 attention을 활용하지 말고, 아예 attention만으로 인코더와 디코더를 만들어보자"라는 아이디어에서 착안되었다.

위 그림처럼 Transformer는 인코더와 디코더 구조로 이루어져있다.
하지만 RNN이 t개의 시점을 갖는 구조였다면, Transformer에선 인코더와 디코더라는 단위가 N개로 구성되는 구조이다.
예를 들어 인코더와 디코더 각각 6개씩 갖는 모델을 보자면, 아래와 같은 그림으로 표현할 수 있다.

여러 개의 인코더와 디코더를 하나의 그림으로 표현한다면 아래처럼 생각할 수 있을 것이다.

여기서 seq2seq과 다른 점은 Encoder의 정보를 압축한 (seq2seq관점에서) context vector라고 불리는 중간층이 없다는 것이다.
하지만 [ I, am, a, student ] 라는 단어의 순차성을 고려할 수 있었던 RNN의 특성을 Transformer에선 어떻게 구현할 수 있을까?
바로 단어의 위치 정보를 알려주는 포지셔널 인코딩(Positional Encoding)을 활용하는 것입니다.
더 딥하게 공부하기 전에 트랜스포머의 주요 하이퍼파라미터를 알고 넘어가보자.
2. Transformer의 주요 하이퍼파라미터
- \(d_{model} = 512 \) : 임베딩 차원 (=인코더와 디코더에 정해진 입/출력 크기, 논문에선 512를 사용 - 언제든 변경 가능)
- \( \text{num_layers}=6 \): 인코더 & 디코더 층 개수 (논문에선 6개의 층을 사용 - 언제든 변경 가능)
- \( \text{num_heads}=8 \): 병렬로 어텐션을 사용하는데, 병렬의 개수 (논문에선 8개를 사용 - 언제든 변경 가능)
- \( d_{ff}=2048 \): 트랜스포머 내부 FFNN 은닉층의 크기 (언제든 변경 가능)
3. 포지셔널 인코딩 (Positional Encoding)
앞서 트랜스포머는 RNN처럼 단어 입력을 순차적으로 받지 않는다고 했다. 따라서 우리는 단어의 위치 정보(position information)를 어떤식으로든 인코더-디코더에 알려줄 필요가 있다. 이때 positional encoding을 활용하게 되는데, 각 단어의 임베딩 벡터에 위치정보를 단순하게 더한 것을 모델의 입력으로 사용하게 된다.

포지셔널 인코딩을 사용한다면 순서 정보가 보존되어 입력 시퀀스를 자연스럽게 받아줄 수 있다.
또한, 같은 단어라고 할지라도, 문장 내 위치에 따라서 transformer의 입력으로 들어가는 임베딩 벡터의 값이 달라져서 조금 더 세련되게 단어 위치 정보를 습득할 수 있는 것이 특징이다.
이때 포지셔널 인코딩 값을 만들기 위해서 sine과 cosine함수를 활용하게 되는데, 이 두 삼각함수의 값을 임베딩 벡터에 더해주면서 단어의 순서 정보를 반영할 수 있다.
$$ \text{PE}_{(pos,2i)}=sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) $$
$$ \text{PE}_{(pos,2i+1)}=cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) $$
위 함수를 이해하기 위해서는 위에서 본 임베딩 벡터와 포지셔널 인코딩의 덧셈은 사실 임베딩 벡터가 모여 만들어진 문장 행렬과 포지셔널 인코딩 행렬의 덧셈연산을 통해 이루어진다는 점을 이해해야한다.
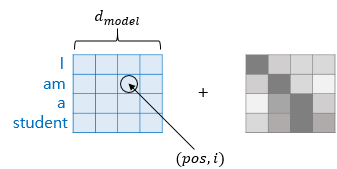
\( pos\)는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, \( i \)는 임베딩 벡터 내의 차원의 인덱스를 의미한다.
따라서 위 수식에 의거하면, 임베딩 벡터 내의 각 차원의 인덱스가 짝수인 경우에는 사인함수의 값을 사용하고, 홀수인 경우에는 코사인 함수의 값을 활용한다.
이젠 아래의 코드를 통해 positional encoding을 구현해보자
import numpy as np
import tensorflow as tf
class PositionalEncoding(tf.keras.layers.Layer):
def __init__(self, position, d_model):
super(PositionalEncoding, self).__init__()
self.pos_encoding = self.positional_encoding(position, d_model)
def get_angles(self, position, i, d_model):
angles = 1 / tf.pow(10000, (2 * (i // 2)) / tf.cast(d_model, tf.float32))
return position * angles
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(
position=tf.range(position, dtype=tf.float32)[:, tf.newaxis], # tf.newaxis를 통해 차원을 하나 추가
i=tf.range(d_model, dtype=tf.float32)[tf.newaxis, :], # tf.newaxis를 통해 차원을 하나 추가
d_model=d_model
)
# 배열의 짝수 인덱스(2i)에는 사인 함수 적용
sines = tf.math.sin(angle_rads[:, 0::2])
# 배열의 홀수 인덱스(2i+1)에는 코사인 함수 적용
cosines = tf.math.cos(angle_rads[:, 1::2])
angle_rads = np.zeros(angle_rads.shape)
angle_rads[:, 0::2] = sines
angle_rads[:, 1::2] = cosines
pos_encoding = tf.constant(angle_rads)
pos_encoding = pos_encoding[tf.newaxis, ...] # ...은 :와 비슷한 용도로 사용 가
print(pos_encoding.shape)
return tf.cast(pos_encoding, tf.float32)
def call(self, inputs):
return inputs + self.pos_encoding[:, :tf.shape(inputs)[1], :]
그리고 50x128의 크기를 갖는 포지셔널 인코딩 행렬을 시각화하여 어떤 형태를 갖는지도 확인해보자
(입력 문장의 단어 개수: 50개 / 단어 임베딩 벡터의 차원: 128)
import matplotlib.pyplot as plt
# 문장의 길이 50, 임베딩 벡터 차원 128
sample_pos_encoding = PositionalEncoding(50, 128) # 포지션은 총 50개. why? 단어가 50개임
plt.figure(figsize=(10, 10))
plt.pcolormesh(sample_pos_encoding.pos_encoding.numpy()[0], cmap='RdBu')
plt.xlabel('Depth')
plt.xlim((0, 128))
plt.ylabel('Position')
plt.colorbar()
plt.show()
여기까지 포지셔널 인코딩에 대해 알아보았다.
다음 포스팅은 Transformer가 활용하는 Attention에 대해 알아보도록 하자.
'딥러닝 > NLP' 카테고리의 다른 글
| [Attention Mechansim] 바다나우 어텐션 (0) | 2022.12.19 |
|---|