![[Attention Mechansim] 바다나우 어텐션](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbGlKqc%2FbtrT5rQa2Uy%2FWc2yZemzd0acSEYxLLphD0%2Fimg.png)
NLP 심화과정 & 딥러닝에서 Transformer와 BERT 레벨의 알고리즘을 공부할 때 필요한 개념인 어텐션 메커니즘, 그중에서도 범용적으로 많이 사용되는 바다나우 어텐션에 대해 알아보자.
이 메커니즘에 대해 알기 위해서는 seq2seq 개념이 선행되어야 이해하기 쉬울 것이다.
단순 닷 프로덕트 어텐션 보다는 조금 더 복잡하지만, 자주 활용하고 한번 테스트 코드라도 작성해 본다면 이해하기가 크게 어렵진 않은 개념이다.
바다나우 어텐션 함수는
Attention(Q, K, V) = Attention Value 로 정의가 되는데,
t: 어텐션 메커니즘이 수행되는 디코더 셀의 현재 시점을 의미
Q (Query): t-1시점의 디코더 셀에서의 은닉 상태
K (Keys): 모든 시점의 인코더 셀의 은닉 상태들
V (Values): 모든 시점의 인코더 셀의 은닉 상태들
를 뜻합니다.
다른 어텐션 메커니즘과 다르게 여기서는 어텐션 함수의 Query가 디코더 셀의 t 시점의 은닉 상태가 아니라 t-1 시점의 은닉 상태임을 주목해야한다.
기본적으로 바다나우 어텐션이 가미된 seq2seq encoder와 decoder를 까보면... 아래와 같은 구조임을 알 수 있다.

바다나우 어텐션 값을 구하기 위해서는 해야할 일은 다음과 같다.
1. Attention Score 구하기
2. Attention Distribution (=attention weights) 구하기
3. Attention Values (Context Vector) 구하기 <<<<< 여기까지가 바다나우 어텐션 값을 구하는 프로세스
( 그 이후 어텐션 값을 활용하여 )
4. 임베딩 된 단어 벡터와 Attention value를 결합하여 s_t를 구할 수 있다
5. 구해진 s_t는 예측값을 구하는데 활용된다.
먼저 첫번째...
1. Attention Score 구하기
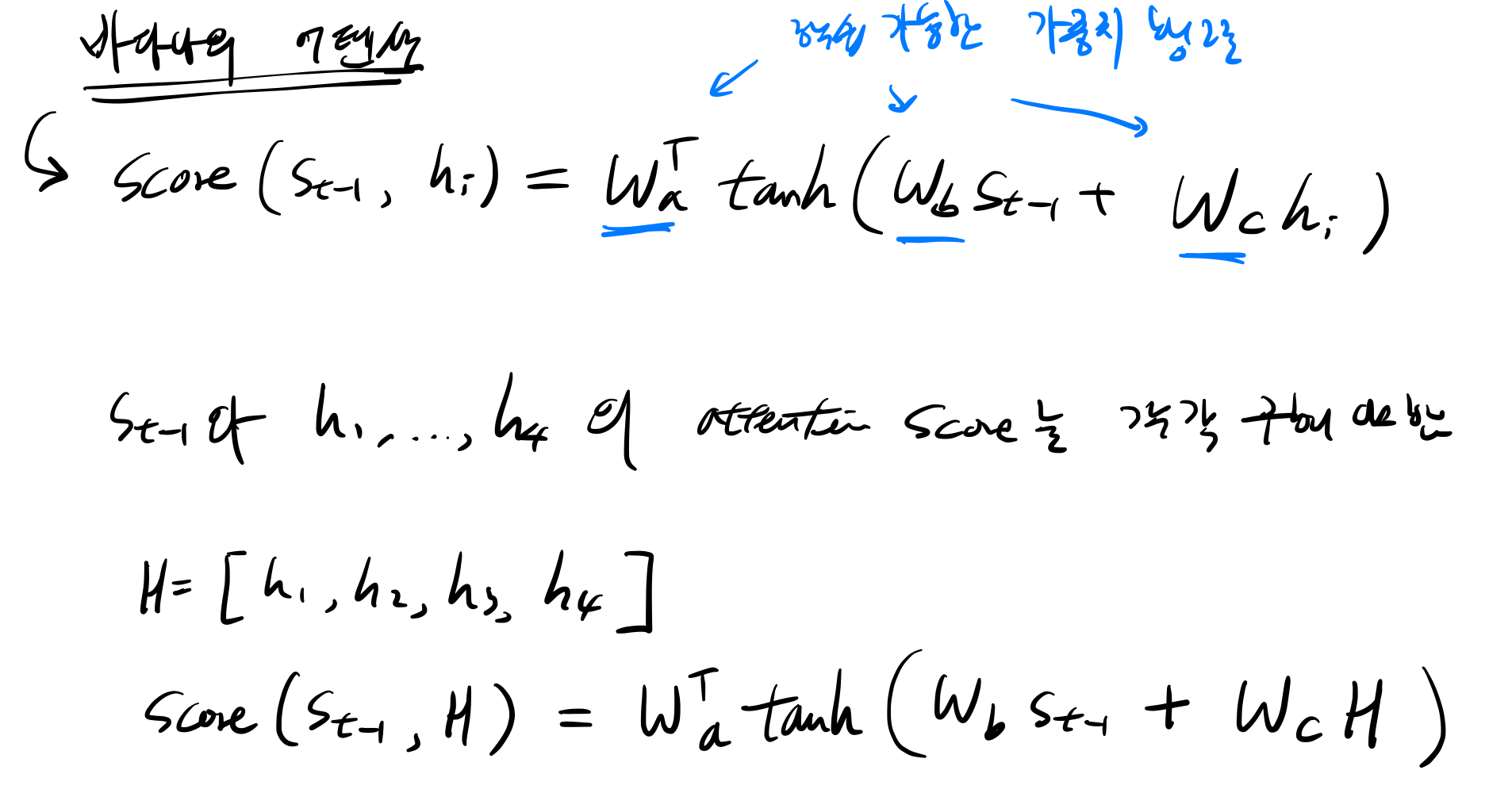
그림으로 보자면

2. Attention Distribution (=attention weights) 구하기
이렇게 attention score를 구했다면, softmax를 이용하여 초록색 벡터인 attention score의 확률분포를 구할 수 있다.
이를 attention distribution 이라고 하는데, 이때 attention distribution의 각각 벡터의 값은 하나의 가중치가 되어 context vector를 구할 때 활용하게 된다.
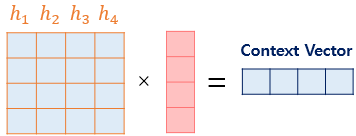
3. Attention Values (Context Vector) 구하기
이젠 준비된 정보들을 하나로 취합하고, 어텐션의 최종 결과값을 얻기 위해서 각 인코더의 은닉 상태와 어텐션 가중치값들을 곱하고 최종적으로 모두 더해야한다 --> 이렇게 되면 가중합을 구하게 되는데, 이 벡터는 인코더의 문맥을 포함하고 있어 context vector라고 불리는 것이 특징이다.
4. 임베딩 된 단어 벡터와 Attention value를 결합하여 s_t를 구할 수 있다 & 5. 구해진 s_t는 예측값을 구하는데 활용된다.
아래와 같이 어텐션 메커니즘을 활용할 수 있게 되는데, context vector와 임베딩된 단어 벡터가 결합하여 최종 decoder LSTM셀을 거쳐 s_t를 구할 수 있게 된다.

따라서 어텐션을 활용하면서 디코더에서 출력 단어를 예측하는 매 시점마다 인코더에서의 전체 입력 문장을 다시 한 번 참고하는 장점을 얻을 수 있다.
그렇다면 벡터로 압축한 정보 손실을 어느정도 상쇄 또는 최소화할 수 있으며, RNN의 고질적인 기울기 소실 문제에 대응할 수 있는 장점이 있다.
[reference: Won Joon Yoo, Introduction to Deep Learning for Natural Language Processing, Wikidocs]
'딥러닝 > NLP' 카테고리의 다른 글
| 트랜스포머(Transformer) - 1 (포지셔널 인코딩) (0) | 2022.12.22 |
|---|