![[딥러닝] 합성곱 신경망 - 직관적으로 convolutional layer 깊이에 대해 이해하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FUWth6%2Fbtr0AyWgmsU%2FAAAAAAAAAAAAAAAAAAAAAEdMM482j3wJnfDoj51r4GXWFY-M390f5_LwCJym3eiR%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3D2HhhcgSNzb7YFOFdLHESR%252Bg4rAA%253D)
본 포스팅에서는 수식적으로 합성곱 연산을 설명하기 보다는 그림에 의존한 직관적인 내용을 이야기 해보겠음
합성곱 연산
완전 연결층(Dense Layer)과 합성곱 층(Convolutional Layer) 사이의 근본적인 차이는 어떻게 될까?
Dense층은 입력 특성 공간에 있는 전역 패턴을 학습하지만, 합성곱 층은 지역 패턴을 학습합니다.
만약 이미지라면 작은 2D 윈도우로 입력에서 패턴을 찾습니다.
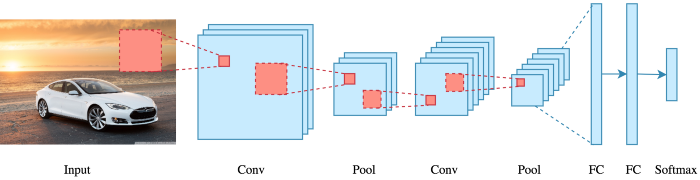
컨브넷은 두 가지 흥미로운 성질을 제공하는데요.
첫째, 학습된 패턴은 평행 이동 불변성(translation invariant)를 갖습니다. 컨브넷이 이미지의 오른쪽 아래 모서리에서 어떤 패턴을 학습했다면, 다른 곳(예를 들어 왼쪽 위 모서리)에서도 이 패턴을 인식할 수 있습니다.
해당 패턴을 학습했기 때문에 위치에 상관없이 비슷한 패턴을 골라낼 수 있는 것입니다. 반대로 완전 연결 네트워크는 새로운 위치에 나타난 것은 설령 다른 위치에서 관측되었을지라도 새로운 패턴으로 학습해야 합니다.
따라서 컨브넷을 활용하면 적은 수의 훈련 샘플을 사용해서 일반화 능력을 가진 표현을 학습할 수 있습니다.
둘째, 컨브넷은 패턴의 공간적 계층 구조를 학습할 수 있습니다.
첫번째 합성곱은 엣지와 같은 작은 지역 패턴을 학습합니다.
두번째 합성곱 층은 첫번째 층의 특성으로 구성된 더 큰 패턴을 학습합니다.
이런 방식을 사용하여 컨브넷은 매우 복잡하고 추상적인 시각적 개념을 효과적으로 학습할 수 있습니다.
아래의 그림을 보겠습니다.

이 고양이가 첫번째 convolutional layer를 지나게 되면, 아래와 같이 고양이의 엣지와 같이 지역적인 특징을 학습합니다. (여기서는 대각선 모양의 패턴들을 학습했다고 볼 수 있겠습니다)

여기서 더 많은 컨브넷을 사용하여 그림의 특징을 학습한다면, 아래와 같이 굉장히 추상적인 패턴을 학습하게 됩니다.
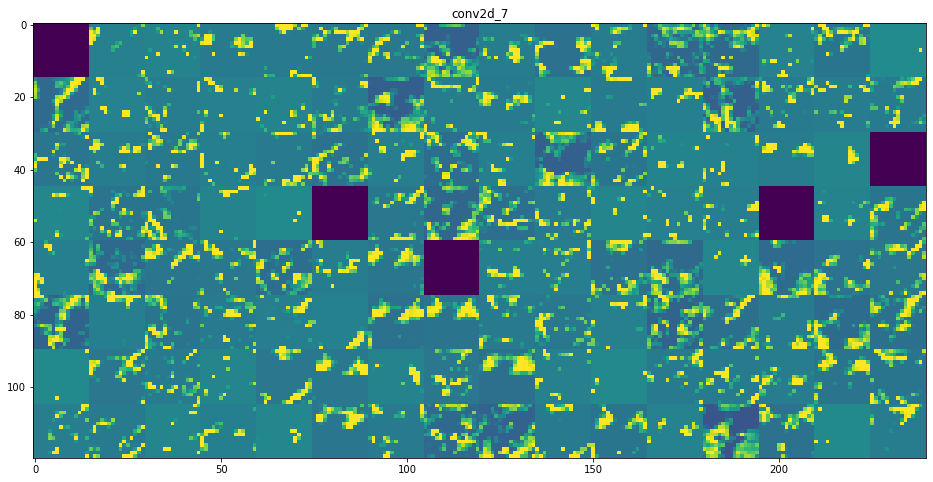
육안으로 "고양이의 어떠한 특징중 한 부분이다"라고 말할 수 없을 정도로 추상적인 모습입니다.
이렇게 학습한 특징을 다른 고양이 사진에서도, 고양이가 어디에 있든 배경 뒤에 있든, 모서리 한 귀퉁에 위치해있든, 저 특징과 일치하는 부분이 보인다면 고양이라고 분류하는 매커니즘 입니다.
아래의 그림을 참고하면 이해가 조금 더 쉬울 것입니다.

따라서, 특징 맵(feature map)이 깊어질수록 class에 대한 정보를 담고 있고, 얕을수록 원본 이미지에 가까운 feature들을 담고 있습니다.
'딥러닝 > VISION' 카테고리의 다른 글
| [Tensorflow] AutoEncoder 오토인코더 구현하기 (0) | 2023.02.26 |
|---|